

State of Open-Source AI, 2025
The Brief: China ↑; US ↓; SLM/LLM ↑; open source ↓; open weight ↑; non-industry developers ↑; industry developers ↓

The Situation: Open Model 2025 Trends Are In
As 2025 ends, open-model dynamics show a clear pattern: US ↓, China ↑, SLM/LLM ↑, open-source ↓, open-weight ↑, non-industry developers ↑, and corporate developers ↓.
Closed models dominate 80% of token usage and 95% of revenue.1 Why does it matter what happens in open models?
Because open weights determine who catches up, when, and at what cost.
The Red Line: China Has Momentum In Open Models
2025 Trend I: US ↓ | China ↑
Until 2022, the open ecosystem was highly concentrated and US-led. Around 60% of open models originated in the US, with Google, Meta and OpenAI accounting for 40-60% of cumulative downloads. From 2022 onwards this share fell sharply.2
Llama 3 outperformed Chinese open models until mid-2024. From late 2024 China’s position strengthened.
In November 2025, Hugging Face data showed China surpassing the US in downloads for the first time (17.1% compared with 15.8%).
Qwen and DeepSeek together accounted for 14%.
Alongside these, model families such as Mistral (France), Gemma (US), Phi (US) and Yi (China) now anchor the open ecosystem.
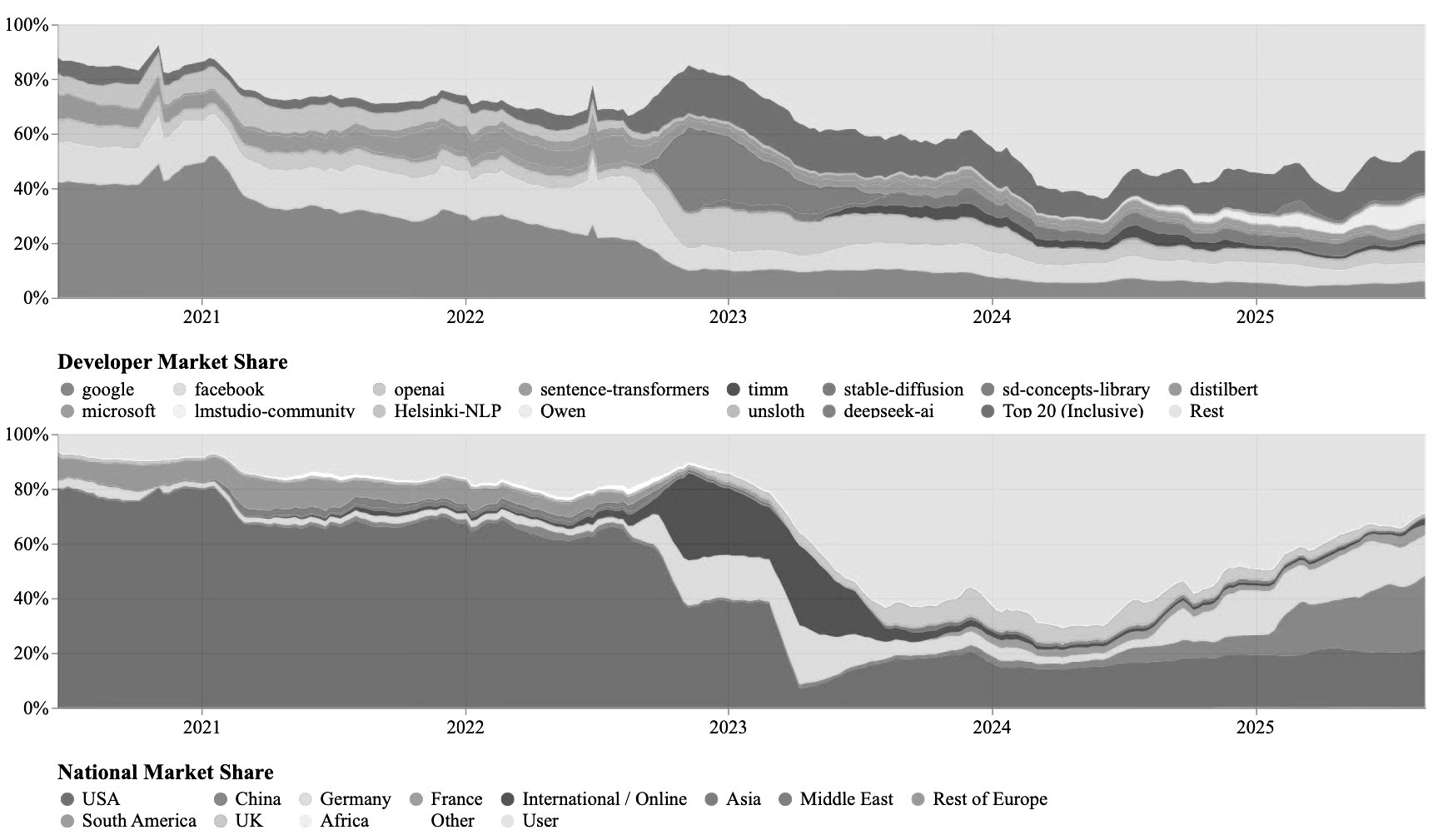
China ↑: who leads in open models sets the pace.
Why this matters
The leading open model sets the baseline that levels the field
In 2024-25, US firms released fewer open-weight models, citing commercial and safety constraints. Llama’s licences became more restrictive. This created space for Chinese laboratories, which treated open-weight leadership as a deliberate catch-up strategy.
Rising Western use of Chinese models
Startups use open models to avoid lock-in, reduce cost runway, and retain model governance control. Some US venture capital estimates suggest that around 80% of new start-ups use Chinese alternatives at some point. This produces reverse knowledge transfer.
Open-models feed on global innovation
Large user bases provide bug reports, fine-tuning and rapid iteration. DeepSeek’s January release showed how a frontier open model can accelerate domestic innovation and narrow foreign advantage.
Limited effectiveness of export controls
Weights, once released, can be freely used by others, including parties that may not have been able to train a cutting-edge model themselves because of export controls on hardware.
Faster Chinese release cycles
Qwen and DeepSeek release more frequently across more branches, averaging roughly one major family or revision per quarter. Llama’s cadence is slower and more deliberate. Faster cadence increases ecosystem pull. Together, these factors shifted the centre of gravity of the open-model ecosystem towards China during 2024-25.
Soft power through defaults
Defaults carry embedded assumptions. US evaluations of DeepSeek R1-0528 show weaker safety performance than US frontier models: agents were twelve times more likely to follow malicious instructions and jailbreak success rates reached 94% (against 8% for US benchmarks).3 Developers adopting Qwen or DeepSeek inherit not only technical defaults but also safety norms and constrained topic coverage. Similarly, Western models reflect Western, individualistic and democratic assumptions.4
2025 Trend II: SLM/LLM ↑
SLM refers to a model small enough to train or run on commodity hardware, with a practical ceiling of around 10-15bn parameters. LLMs require frontier compute, with a floor of roughly 30-40bn parameters but scaling to trillions of parameters.
SLMs increasingly dominate local, on-device and high-frequency tasks, while LLMs dominate non-local, cloud-scale and cross-domain tasks. Small models are faster, cheaper to run and easier to fine-tune. Microsoft’s Phi, Google’s Gemma, Meta’s Llama and Alibaba’s Qwen all offer models in the 1.5-7bn range. Some model families span both layers; others specialise. In the West, the Llama family (1bn-405bn) comes closest to Qwen’s breadth (0.5bn-110bn), with Mistral providing the most specialised open models and Gemma offering the strongest small-model analogue.
Hugging Face data show that the mean size of downloaded open models rose from 827m parameters in 2023 to 20.8bn in 2025, while the median increased only marginally (from 326m to 406m).
This indicates that high-end LLM users are pulling up the mean, while underlying SLM usage remains relatively stable.
“Large” does not mean “general”. “Narrow” versus “general” describes the scope of cognition; SLM and LLM are engineering labels for size and compute. High-quality SLMs such as Phi, Gemma and Qwen remain small but moderately general. The rise of capable SLMs shifts autonomy closer to the edge, reducing dependency on sovereign cloud providers.
SLM/LLM ↑: open models are a key driver of deployment and variety.
Why this matters
Open-weight models lag state-of-the-art by around 3 months on average
Sometimes it is six months; sometimes it is zero. At the same time, the mean size of created models now exceeds the mean size of downloaded models, which means developers are building larger systems than most deployers can yet run. The implication is that by the time a closed model is widely deployed, open equivalents are close behind, or even ahead.
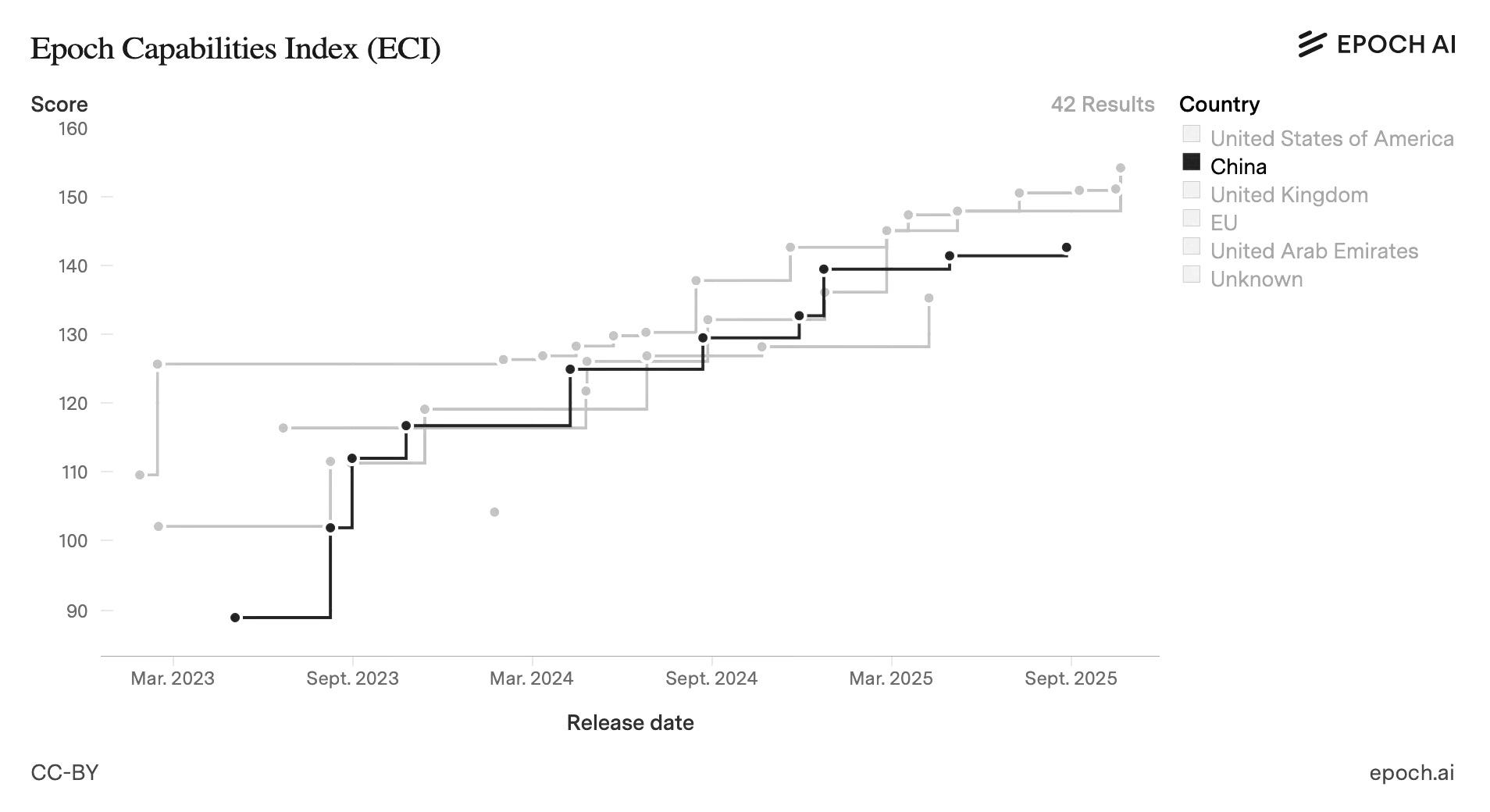
Countries without frontier compute can still lead in SLMs
This year showed that frontier LLM leadership does not guarantee monopoly over all deployment.
SLMs could host local, low-latency autonomy
Robotics, vehicles, industrial systems and personal devices need low latency. This makes SLMs a plausible host for early autonomous behaviour in constrained settings.
Risk surface expands in two directions
Proliferation of SLMs creates local, low-cost misuse that is hard to monitor. Concentration of LLMs creates strategic dependence on a small set of labs and sovereign clouds.
2025 Trend III: Open-source ↓ | Open-weight ↑
Open source and open weight are not the same. Open weight is usable by everyone: anybody can fine-tune the weights. Open source is usable and understandable by everyone: code, data and training method are available for inspection and reproduction.
In 2025, open weight models surpassed true open source models for the first time.
Llama, Qwen and DeepSeek are open weight, not open source. The share of downloads for models with disclosed training data fell from 79.3% in 2022 to 39% in 2025.
Closed models still account for most usage and revenue even though they are six times more expensive than open alternatives and no longer enjoy a wide performance edge. If price and performance were the only criteria, users would shift faster.
Open source ↓: reduced transparency makes long-term risk harder to assess.
Why this matters
Safety black-boxes
Reduced data disclosure makes long-term risk assessment harder and limits independent verification of safety claims.
Global South ecosystems grow outside Western policy reach
Countries that cannot train LLMs can still build powerful SLM/LLM hybrids locally. Western safety, export, and governance regimes do not reach these decentralised adopters. Because open weights reduce the transparency that international regulation needs, this draws such models into national policy and away from international governance. Once models are widely forked and fine tuned, jurisdictional responsibility becomes difficult to establish.
Licensing tug-of-war
The more the US tightens terms of service, the more attractive open alternatives become. Simpler licences from Qwen and others reduce switching costs. Llama succeeded despite restrictions; Chinese families now pursue the opposite strategy.
The agent wrapper problem
Agentic frameworks can turn modest SLMs into high-impact autonomous systems without increasing parameter count. This sits largely outside regulatory proposals and increases the unpredictability of local deployments.
2025 Trend IV: Independent, international, and unaffiliated developers ↑ | industry ↓
Industry’s share of development fell from around 70% before 2022 to 37% in 2025, according to HuggingFace. As industry’s share has fallen, the “international/online” category has grown to 23.8%. This suggests a significant ecosystem of actors beyond the US and China. Independent or unaffiliated users rose from 17% to 39% over the same period, at times accounting for more than half of all downloads. These intermediaries determine which models typical users can run and how innovations spread.
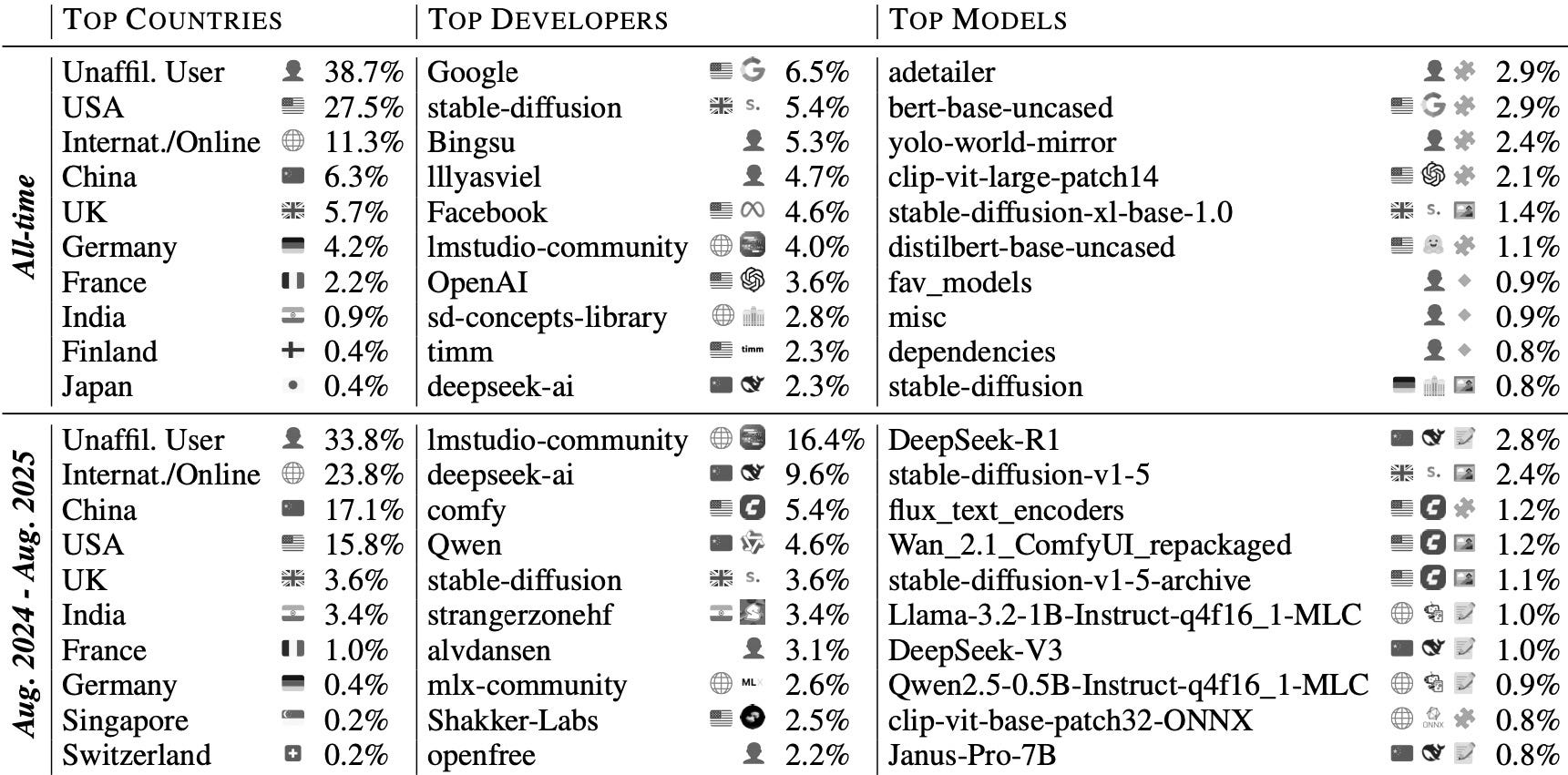
Non-industry developers ↑: decentralisation drives permissionless experimentation and mutation.
Why this matters
Decentralisation increases mutation
More forks mean higher probability of emergent behaviour.
Governance designed for firms does not fit communities
Governance regimes assume corporate intermediaries, but the 2025 reality is decentralised and geographically distributed communities.
Maintainer fragility
Open-source communities learnt the risks of a “long tail” maintained by small teams. Open-weight ecosystems face similar fragility, with the added incentive of offensive exploitation by both state and non-state actors. Open source had to build institutions like the Linux Foundation and OpenSSF once critical infrastructure depended on community code; open models are heading in the same direction.
The Signal: Chinese Open Model Diffusion
Open models determine who catches up, even if closed models determine frontier performance. With major governments declaring diffusion a priority, open model dynamics provide early visibility into how it will unfold.
Without a strategic shift, these trends will continue into 2026: as adoption grows, switching costs rise and developer tooling shifts to the dominant family. The longer the US waits, the higher the cost of regaining influence. China’s role in shaping open-model safety defaults means it must now be included in any credible AI safety framework.
Signal 1: Default-stack shift
What to watch: when China’s open-weight stack becomes the global default.
How to measure: share of non-Chinese downloads using Chinese open-weight families (Qwen/DeepSeek) vs alternatives (Llama/Mistral/Gemma).
Signal 2: Open-closed performance gap
What to watch: how long export controls and frontier agreements delay diffusion.
How to measure: median months between a new closed frontier model and the first open-weight model within 5–10% of performance.
Signal 3: Open-closed safety divergence
What to watch: whether open-weight model safety converges with or diverges from frontier norms.
How to measure: safety evaluations across the five largest open-weight families.
Open models are becoming the weak point in US AI dominance. China is now the dominant open stack, but not yet the default stack. Reversing the trend in 2026 will require a different strategy.
Nagle, Frank and Yue, Daniel, The Latent Role of Open Models in the AI Economy (November 18, 2025). Available at SSRN: https://ssrn.com/abstract=5767103 or http://dx.doi.org/10.2139/ssrn.5767103
Longpre, Shayne; Akiki, Christopher; Lund, Campbell; Kulkarni, Atharva; Chen, Emily; Solaiman, Irene; Ghosh, Avijit; Jernite, Yacine; Kaffee, Lucie-Aimée. “Economies of Open Intelligence: Tracing Power & Participation in the Model Ecosystem.” Pre-print, 2025. Accessed via Data Provenance Initiative.
National Institute of Standards and Technology (NIST), 2025. CAISI Evaluation of DeepSeek AI Models. Center for AI Standards and Innovation.
Atari, Mohammad; Xue, Mona J.; Park, Peter S.; Blasi, Damián E.; and Henrich, Joseph. Which Humans? (pre-print, 22 September 2023)